
How to Extract or Copy Text from PDF Image: 7 Solutions
 24.6K
24.6K
 1
1




PDF Converter OCR
Batch Copy or Extract Text from PDF Images

“I got a PDF image file and need text content contained in it. Is there a way to extract text from such a document without retyping the text completely?”
A host of people in Quora platform has raised similar problems. They tried to copy and paste the text in the PDF image directly but found it impracticable. Indeed, it is a big challenge to extract text from PDF image if you don’t have an OCR program in the palm of your hand. Take it easy! This article will shed light on how to copy text from PDF image in 7 hassle-free ways.
 Cisdem PDF Converter OCR
Cisdem PDF Converter OCR
Batch Copy or Extract Text from PDF Images
- Extract and copy texts from PDF image or scanned PDFs with high accuracy.
- Recognize texts from PDF images in 50+ languages: English, French, Arabic, Chinese, German and so on.
- Export PDF image to editable Word, Excel, PowerPoint, ePub, Text, HTML and so on.
- Fast to extract texts from multiple PDF images simultaneously.
- Create searchable PDF from an extensive list of formats.
- Merge many inputs into a single output PDF.
- Simple-to-use interface and excellent performance.
 Free Download Windows 10 or later
Free Download Windows 10 or later  Free Download macOS 10.14 or later
Free Download macOS 10.14 or later
Accurate OCR Software: Copy Text from PDF Image Offline
Have been offering PDF solutions for years, we fairly understand our users. Most of them want to have a try on online free solutions in the beginning, but pick a dedicated program for their work in the end, because time saving and efficiency are always prior to the cost. Therefore, we put those highly accurate solutions to extract text from PDF image on the top of our list. You can check the details and download for a free try.
#1. Cisdem PDF Converter OCR
Cisdem PDF Converter OCR is a dedicated PDF converter and creator, used for both simple and demanding tasks. Powered by smart OCR technology, it can accurately extract text from PDF images and complex documents, including those with tables or handwritten content. Besides, it has an OCR accuracy of 99%, so there's no need for manual checking and correction.
Key features include:
- Multi-format conversion: Export PDF to Word, Excel, PowerPoint, totally 15+ formats.
- OCR functionality: Transform scanned PDFs/images into searchable, editable files (PDF, Word, Excel, etc.) while preserving formatting.
- Language support: Recognize text in over 50 languages from PDF images.
- Batch processing: Convert multiple PDF files at a time.
How to Copy Text from PDF Image or Scanned PDF?
- Download and install Cisdem PDF Converter OCR on your Windows or Mac.
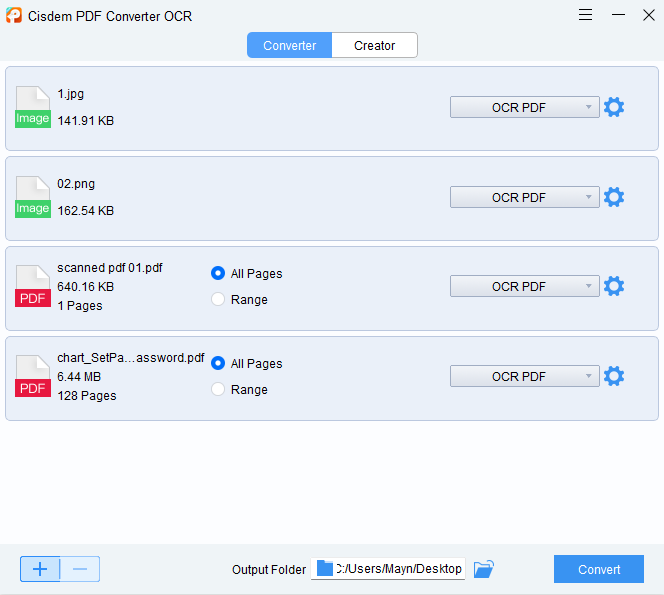
Free Download Windows 10 or later Free Download macOS 10.14 or later - Start the program. Select the Converter tab and drag one or multiple PDF images/scans into the working zone. You need to download OCR module for the first use.
![extract text from pdf cisdem01]()
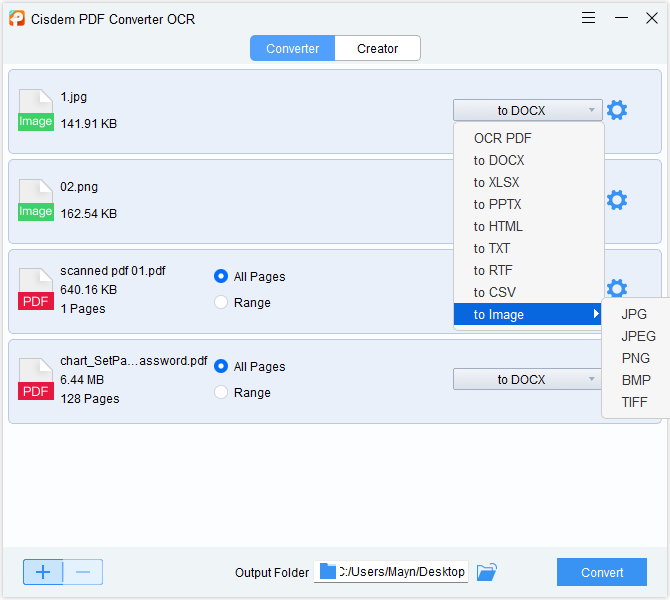
- Select an editable format from the output drop-down list, DOCX, DOC, TXT or any others.
![extract text from pdf cisdem02]()
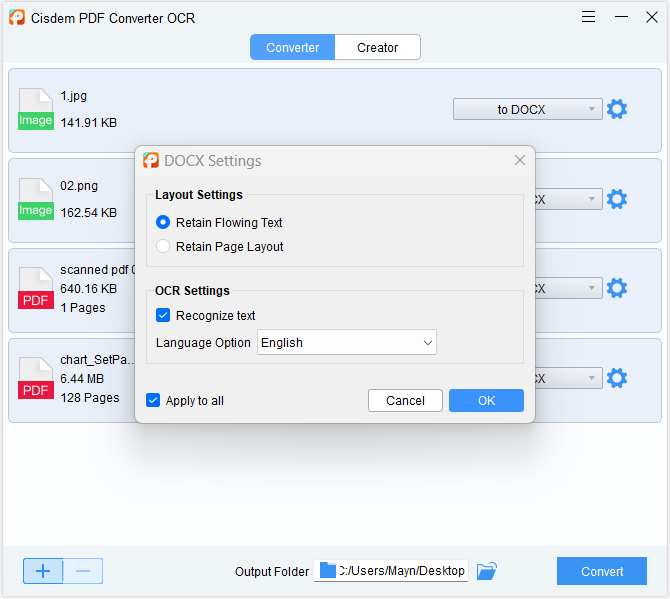
- Click the Gear icon on the right side and make the output settings as per your preference.
![extract text from pdf cisdem03]()
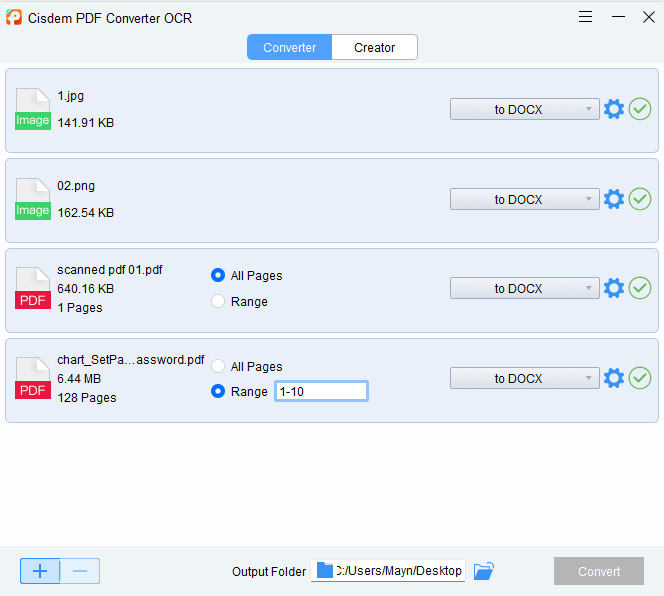
- After completing the adjustments, choose an output folder and continue with Convert. Green check marks mean success and navigate you to the extracted file.
![extract text from pdf cisdem04]()
You can also refer to the video tutorial to extract or copy text from PDF image:
#2. Adobe Acrobat
Adobe Acrobat is a powerful and versatile PDF editor, which is more suitable for professionals and businesses. It can cover almost all of your PDF needs, including extracting text from scanned or image-based PDF files. You can directly recognize the text utilizing its Enhance Scans tool, or convert PDF images into editable and copyable file formats. However, its high subscription fee has discouraged lots of people.
How to Extract Text from PDF Image in Acrobat?
- Open PDF Image with Adobe Acrobat.
- Go to Tools > Enhance Scans.
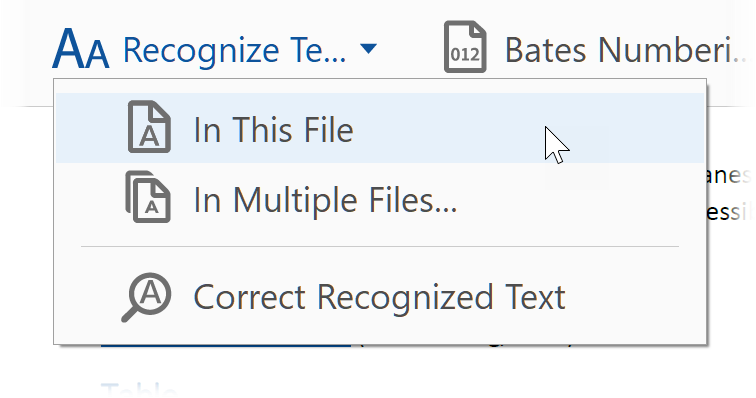
- Go to Recognize Text > In This File and select file language to start Adobe OCR on the PDF image.
![extract text from pdf image in adobe01]()
- Now you can extract text or copy text from the PDF image file in Acrobat.
- (Optional) If you want to save the PDF image as text, go to Tools > Export PDF and select an output format.
![extract text from pdf image adobe02]()
.png)
#3. Microsoft OneNote
Microsoft OneNote is one cross-functional note-taking software that encourages users to create searchable digital notebooks, make handwritten notes and sketch diagrams. Thanks to its built-in OCR capabilities, all text in an image or PDF file opened in OneNote can be searched and copied without difficulties.
How to Copy Text from Image in PDF Using OneNote?
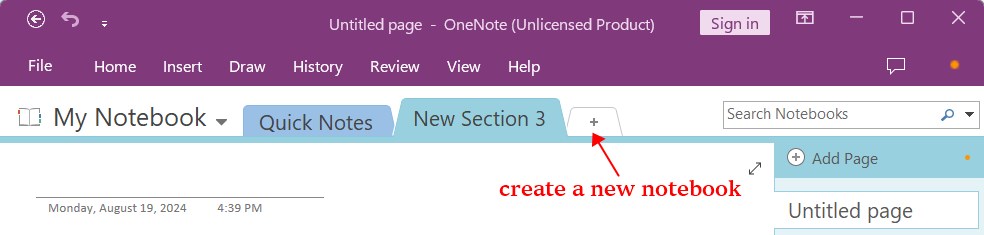
- Launch the OneNote application, open an existing notebook or create a new notebook.
![extract text from pdf01]()
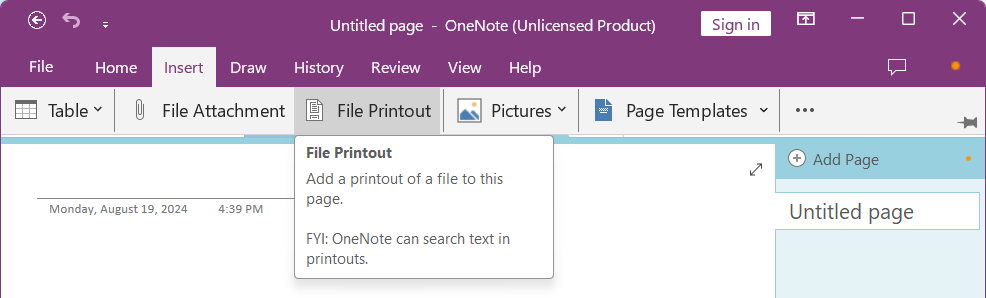
- Choose Insert tab > File Printout to insert your PDF image file into the OneNote.
![extract text from pdf02]()
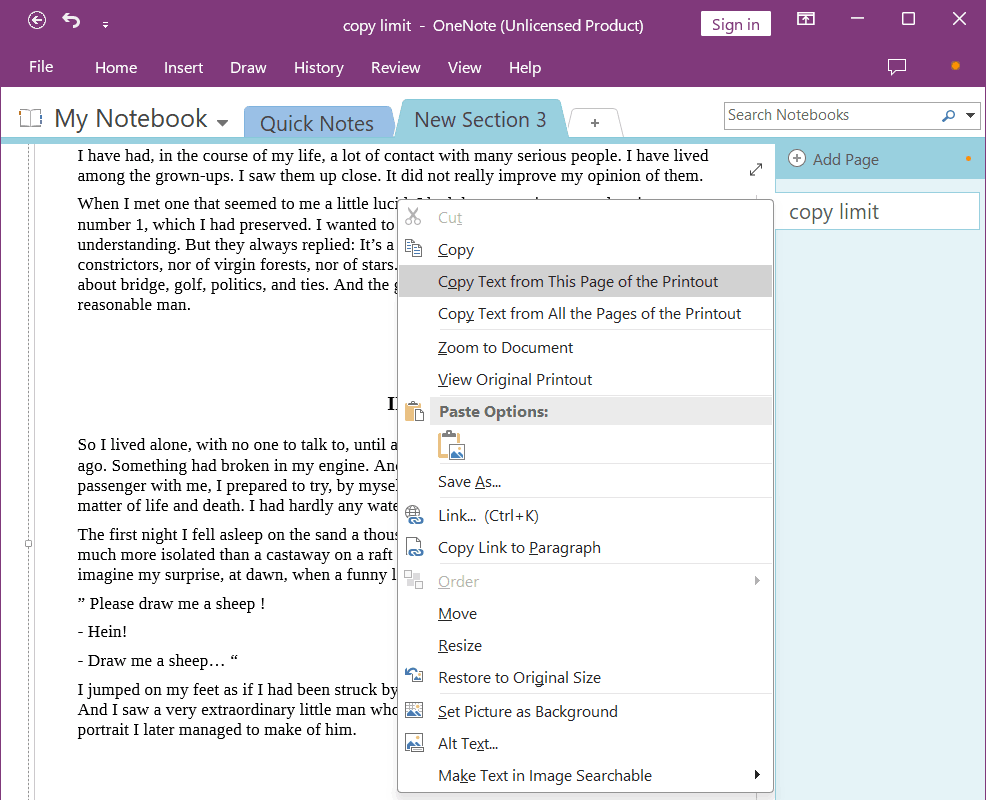
- Scroll down to find the PDF page from which you’d like to copy the text, right click on it and click Copy Text from This Page of the Printout.
![extract text from pdf03]()
- The copied text will be on the clipboard, paste it in the place where you want to.
Web-Based Solutions: Copy Text from PDF Image Online
Powerful enough though dedicated software on the computer is, some people still turn to online free solutions to cut costs and escape download. Therefore, here we have picked out 3 top and convenient online tools to help users extract text from PDF image without difficulties. Each tool has its advantages and limitations.
#1. Google Docs
Google Docs is an online free service offered by Google to work on PDF, image, word and other documents. It has built in an OCR technology, which can convert uncopyable text in images and scanned PDFs into editable. Plus, you can export the results to multiple files, including word, plain text, epub and HTML.
Advantages:
- It supports image and PDF input.
- The recognized text will be displayed under the original image, so you can compare and modify the results before exporting the text.
Disadvantages:
- Process one file at a time.
- It works poor when the imported file has a complex formatting. Some recognition errors occur and the formatting is severely damaged.
How to Extract Text from PDF Image in Google Docs?
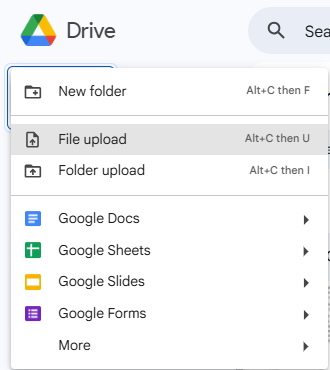
- Go to your Google Drive and upload your file.
![copy text from pdf image google docs01]()
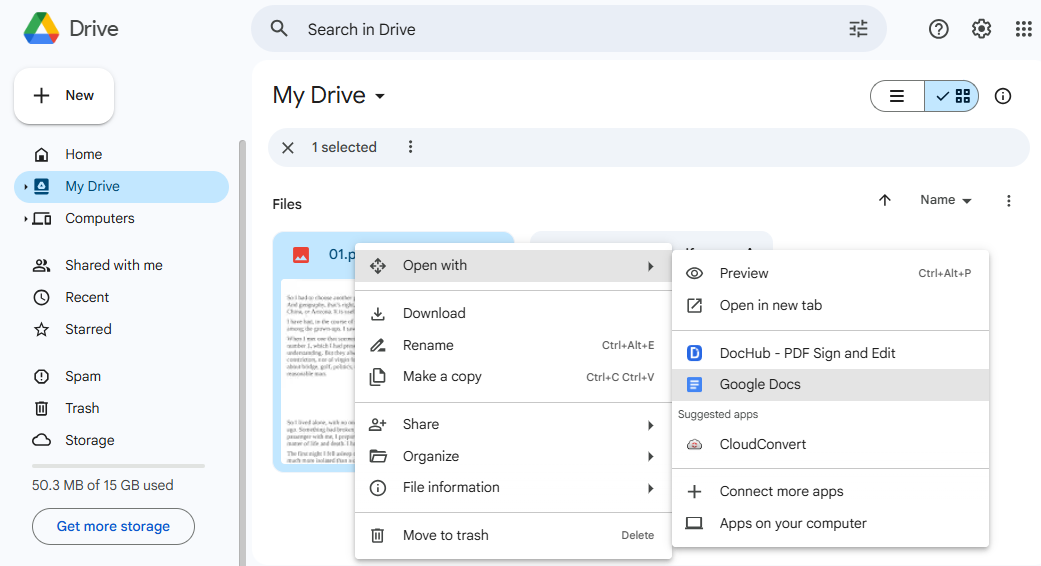
- Right click on the imported image or PDF, open it with Google Docs.
![copy text from pdf image google docs02]()
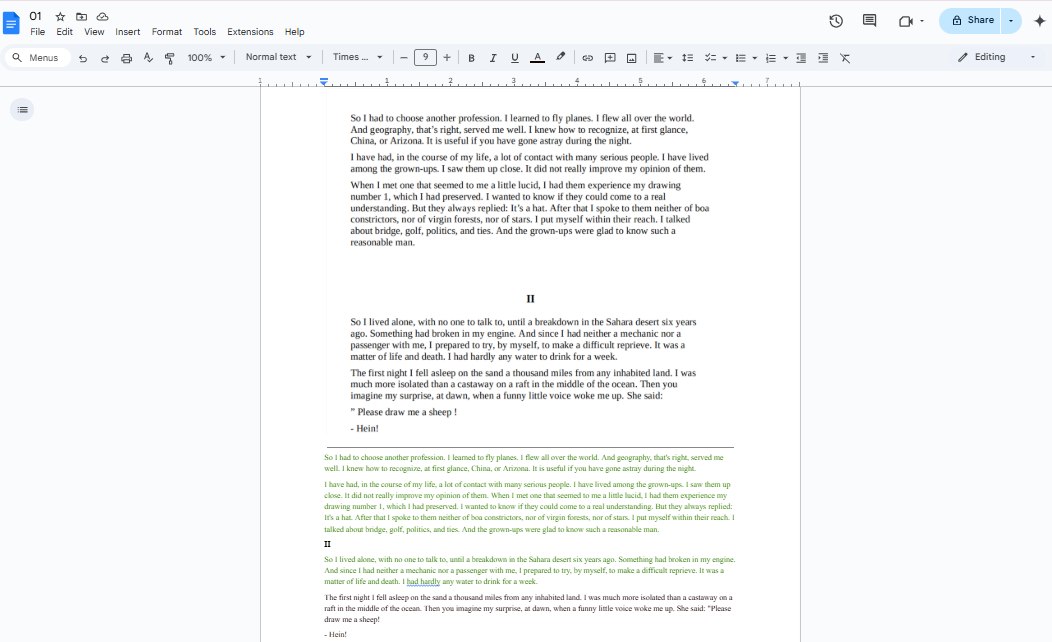
- As shown in the figure, the original image is above and the recognized text (green) is below.
![copy text from pdf image google docs03]()
- You can edit the text easily and download the extracted text as word, text or other formats.
![copy text from pdf image google docs04]()
#2. OnlineOCR
OnlineOCR (onlineocr.net) is a simple online OCR tool to directly extract or copy text from PDF image or image files, the recognized text will be displayed on the webpage for easy and fast check. In addition, it supports exporting PDF image as Word or Excel. But you will have to manually revise the OCR errors.
Advantages:
- Over 40 recognized languages.
- The extracted text will be displayed on the board and can be edited before downloading the output.
- There are no restrictions on the size of the imported files and the number of pages. Also, you can process unlimited tasks.
Disadvantages:
- Extract text from only the first page of multi-page PDF.
- The maximum file size is 15 MB.
- Process one file at a time.
- Only support 3 kinds of output formats: docx, xlsx, txt.
- Many annoying ads are around the working area.
How to Copy Text from PDF Image for free?
- Go to Onlineocr.net.
- Click SELECT FILE to upload a PDF image.
- Choose a file language from the list.
- Select output as Text Plain or others.
- Click CONVERT to start OCR your PDF image to text.
- Copy the recognized text from the output board or download the output file directly.
![onlineocr pdf image]()

#3. Convertio
Compared to OnlineOCR, Convertio supports more file languages and more output formats. But the main reason why I recommend Convertio OCR is that it helps to perform OCR on a file consisting of 2 languages, which will greatly improve the OCR accuracy when dealing with bilingual files. However, you are only allowed to convert 10 pages for free.
Advantages:
- Allow batch converting PDF image files into editable and copyable files.
- Extract text from bilingual PDF image files.
Disadvantages:
- The total number of pages uploaded cannot exceed 10 pages.
- Recognize files slowly.
- Distracting ads and pop-ups.
How to Copy Text from PDF Image Online Free with Convertio?
- Go to Convertio OCR.
- Upload one or more PDF images to the program.
![convertio pdf image01]()
- Choose 1 or 2 file languages, select output format as Text and fill in the page numbers you want to extract text from.
![convertio pdf image02]()
- Then click Recognize to start OCR.
- Download the text file and you will be able to extract or copy text from the PDF image.


Tech Users: Extract Text from PDF Image in Python
When entering "Extract Text from PDF" in Google, we found that most people are eager to know how to extract text from PDF using Python.
Actually, Python has multiple well-integrated libraries that can help you to extract text from PDF files effectively, like PyPDF2, PyMuPDF, PDFQuery, PDFMiner, PDFPlumber, etc. Here, we will take one of these most commonly used libraries as an example--PyPDF2.
PyPDF2 is a free, open-source Python library, capable of performing a lot of operations on a PDF, like merging, splitting, cropping and extracting text from PDF.
How to Extract Text from PDF in Python?
- Install Python. Make sure that you have a Python environment, if not, download it from here.
- Install pip in Python. Download it here and run the following code to install:
pip.python get-pip.py
- Install PyPDF2. Simply enter the following command:
pip install PyPDF2
- Extract text from PDF. You can perform text extraction like this:
from PyPDF2 import PdfReader
reader = PdfReader("example.pdf")
page = reader.pages[0]
print(page.extract_text())
- You can also determine the text orientation you want to extract, e.g:
# extract only text oriented up
print(page.extract_text(0))
# extract text oriented up and turned left
print(page.extract_text((0, 80)))
Conclusion
7 ways to extract or copy text from various PDF would be quite enough for you, and for many users seeking a solution on this, they give more credits to a professional standalone OCR program, which is safer to use, faster to process OCR, more accurate on results, even there are extended features offered to boost your productivity on working with PDF files. What about you? Do you have better advice on this? You can share to us in the comment.
Free Download Windows 10 or later Free Download macOS 10.14 or later

Carolyn has always been passionate about reading and writing, so she joined Cisdem as an editor as soon as she graduated from university. She focuses on writing how-to articles about PDF editing and conversion.

Liam Liu takes charge of the entire PDF product line at Cisdem and serves as the technical approver for all related editorial content. He has deep expertise in PDF and document management technologies and nearly a decade of development experience.
Cecilia K. Hill
I have more than 50 images to extract, Cisdem PDF Converter OCR has saved me a lot of time. Thanks a lot.