PDF often holds a variety of important data in table format. They are fine for human reading or printing, but if you need to extract table from PDF files for Data collection, extraction, and further analysis, then they can be a problem.
Copying and pasting a table from a PDF file into excel is time consuming and hard, especially when dealing with non-searchable PDFs or tables in images.
Therefore, in this article, we will introduce the 6 main ways to extract table from PDF file. We will show how Cisdem, Tabula, SmallPDF, and Camelot perform their respective tasks of extracting tables from PDF file and compare different options to help you select the best fit for specific use cases.
 Free Download Windows 11/10/8/7
Free Download Windows 11/10/8/7  Free Download macOS 10.14 or later
Free Download macOS 10.14 or later
Luckily, There are many different ways to extract table from PDF file, Below are the six most common ways:
While you could still extract text from PDFs by copy-pasting content, extract text from PDFs is way more complicated!
We all know how helpful the copy-and-paste function is. Open a PDF files and use Alt+Tab, Ctrl+C, and Ctrl+V to do the labor work!
But, copying and pasting rarely maintains the table structure. You lost all formats, Columns & rows get mixed and a lot of review and reformatting are required.
If you only have one or two PDF files to handle, this is just fine. But if you have multiple PDF files and need to do it daily, then this becomes a copy and paste nightmare.

PDF converters is what we think are the most efficient method to extract tables from PDF files.
PDF converters allow one to easily extract table from PDF files offline and get the extract data in Excel or CSV format which promise data quality & data security.
With a PDF Converter you simply need to upload the PDF document and choose the output format.
Bellow are some top PDF convertor software:
In our test, Cisdem PDF Converter OCR extracts and best converts tables in PDF. It is AI-based and provides the full solution to extracting data from PDFs. It supports both scanned images and documents and native PDF files. In addition, it comes with advanced OCR technology which can read texts, data, tables from images with 100% accuracy.
Here’s a quick demo of how to use Cisdem PDF Converter OCR to extract table from PDF files:
Cisdem PDF Converter OCR caters to both individuals and businesses. More than 100000 professionals trust Cisdem to convert images and PDF documents to actionable text. Download and install Cisdem PDF Converter OCR on your Mac or Windows to see how it can help you save more than 500 hours per month.
Free Download Windows 11/10/8/7 Free Download macOS 10.14 or later


You may use some PDF Converters to extract tables from PDF file only to find that the output Excel or Word file are actually full pages in an image format. When you try to click or select a sentence, it will only allow you to select the whole page as a image.
This is the result of lack OCR capability. But this is what we consider a very important function of PDF Converter software, as many PDFs are created from a scanner machine or a mobile app. Data in this files are not machine readable, users are not allowed to extract or copy any text from such a PDF image without OCR.
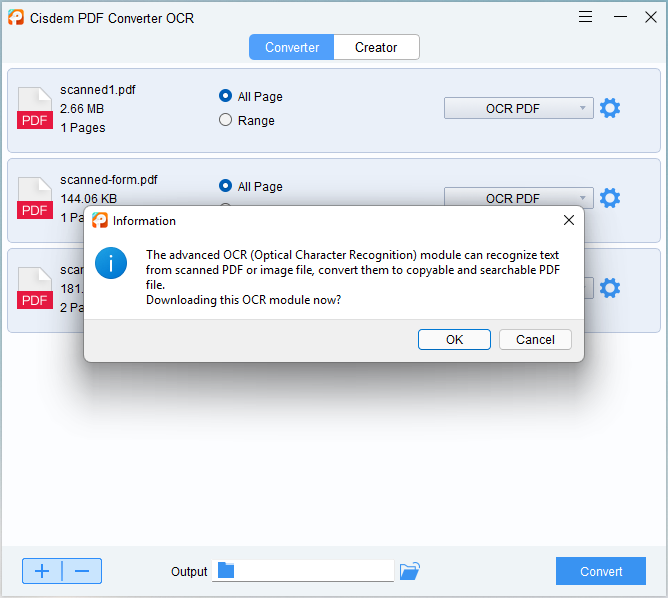
Cisdem comes with build in OCR technology it supports almost all PDF and image formats you can use it to extract tables from
* Invoices
* Receipts
* POs
* All kinds of license
* Passports
* Bank statements

To extract tables from PDF or images you can also outsourcing these services.
There are many websites online that provide this exact service.
The upside is that this can reduce your costs and data-entry expert will take care of your requirements and can parallelize your workflow.
The downside is that quality control & data security are serious concerns. Also, it might become unsustainable and prohibitively expensive in the long run.
Note: Do not do this if the table contents are personal or sensitive!Tabula.py
If you need a free and open source way to extract tables from PDF file, then Tabula is what you are looking for.
The Tabula websites says that Tabula was created “by journalists for journalists”.
What Tabula impress us is that it lets you upload an entire document and select just the tables you want.
It handles one table at a time, and supports to output it as CSV, TSV of JSON file.
Unlike Cisdem PDF Converter OCR, Tabula will return a spreadsheet file which you will need to review and revise manually. Also, Tabula does not support OCR, so it can only handle normal PDF files.
Tabula uses an open-source library called Tabula-Java, and Java environment is necessary for this desktop program.
Download and install Tabula on your Mac or Windows, and clicked on the tool icon. It will open in your web browser.



Note: Tabula only works on text-based PDFs, not scanned images or documents (which are more commonly used)! And you can only upload one file at a time and you need to select the table that needs to be converted.
If you are looking to extract table from PDF without installing any software, then you can use online PDF converters.
There are many online PDF Converters on the market, smallpdf, ilovePDF, and cometdocs are three of the most popular sites which off basic PDF table extraction capabilities.
These online sites are free to use, and compatible with any operating system. You just upload a PDF and download the output.
But, PDF to Excel conversion is more complex than convert PDF to word, most online tools gives jumbled outputs that require quite some review, editing and clean-up.



Note: Online PDF converters are not equipped to handle files in batch. And it can’t handle PDF files with complex table structures.
If you’re a coder, and want to extract tables from PDF programmatically, you can use Python to extract data from PDF documents or images, too!
All you need is the right library. Here the top 3 Python libraries for extracting table from PDFs.
Camelot: This Python library is excellent for extract tables from PDFs. It will auto detects table and supports customizable table extraction, you can set to export tables to formats like CSV, Excel, JSON, HTML & Sqlite. But Camelot only works on text-based PDFs, not scanned images or documents.
Tabula-py: It is a simple Python wrapper of tabula-java. It can be use to convert PDF tables to pandas DataFrame. As the name suggests, it requires Java. With it, you can extract tables from PDF into CSV, TSV or JSON file. It has the same extract accuracy of the tabula app; If you want to check the performance of tabula-py, I highly recommend you to try tabula app. Also, like Tabula app, tabula-py only works with normal PDF files.
Now that we have showed you the main ways to extract table from PDF, each have its own advantage and disadvantages, to help you find the best method, we have listed the pros and cons of each method in the table below.
| Method | Advantages | Disadvantages |
|---|---|---|
| Copy & Paste |
Method for a small number of PDF files No extra software required |
Time consuming Prone to errors Need to review and revise Only can copy and paste from normal PDF files. |
| Cisdem PDF Converter OCR |
Easiest method for PDF to Excel conversion Keep format and layout Can choose which page to extract tables from Supports scanned and normal PDF files |
Need to download software |
| PDF Table Extractor |
Extracts data from a table quickly and accurately Extracts table to excel, csv, html, etc. |
Need to download software Only works on normal PDF files |
| Online PDF Converter |
Free No need to download software |
Only works on normal PDF files No way to extract data in bulk Common formatting errors |
| Python |
Free Works automatically |
Requires code knowledge |
In this blog, we presented the four most popular methods to extract table from PDF or images.
Choosing the right method will saves your time over manual data entry. Especially if need to batch extract tables from PDFs or images.
In our test, Cisdem PDF Converter OCR can extract table from normal or scanned PDF files to Excel with 99% accuracy. Now, no more retype and revise, spend your time and resources on more important company tasks.
Download it now to see why customers trust Cisdem to process millions of documents, and saves huge amount of time which can be better spent on direct customer service.
Free Download Windows 11/10/8/7 Free Download macOS 10.14 or later

Carolyn has always been passionate about reading and writing, so she joined Cisdem as an editor as soon as she graduated from university. She focuses on writing how-to articles about PDF editing and conversion.




